Hi, I am Zihui Xue (薛子慧), and I usually go by Sherry. I am final-year Ph.D. candidate at UT Austin, advised by Prof. Kristen Grauman.
I was a Student Researcher at Google DeepMind in London (2025) and a visiting researcher at FAIR, Meta AI (2023-2025). I obtained my bachelor's degree from Fudan University in 2020.
My research interests lie in video understanding and multimodal learning, with a recent focus on video-language models.
Zihui Xue,
Yale Song,
Kristen Grauman,
Lorenzo Torresani
CVPR 2023 (Hightlight)[paper][webpage]
Multimodal perception and self-supervised learning
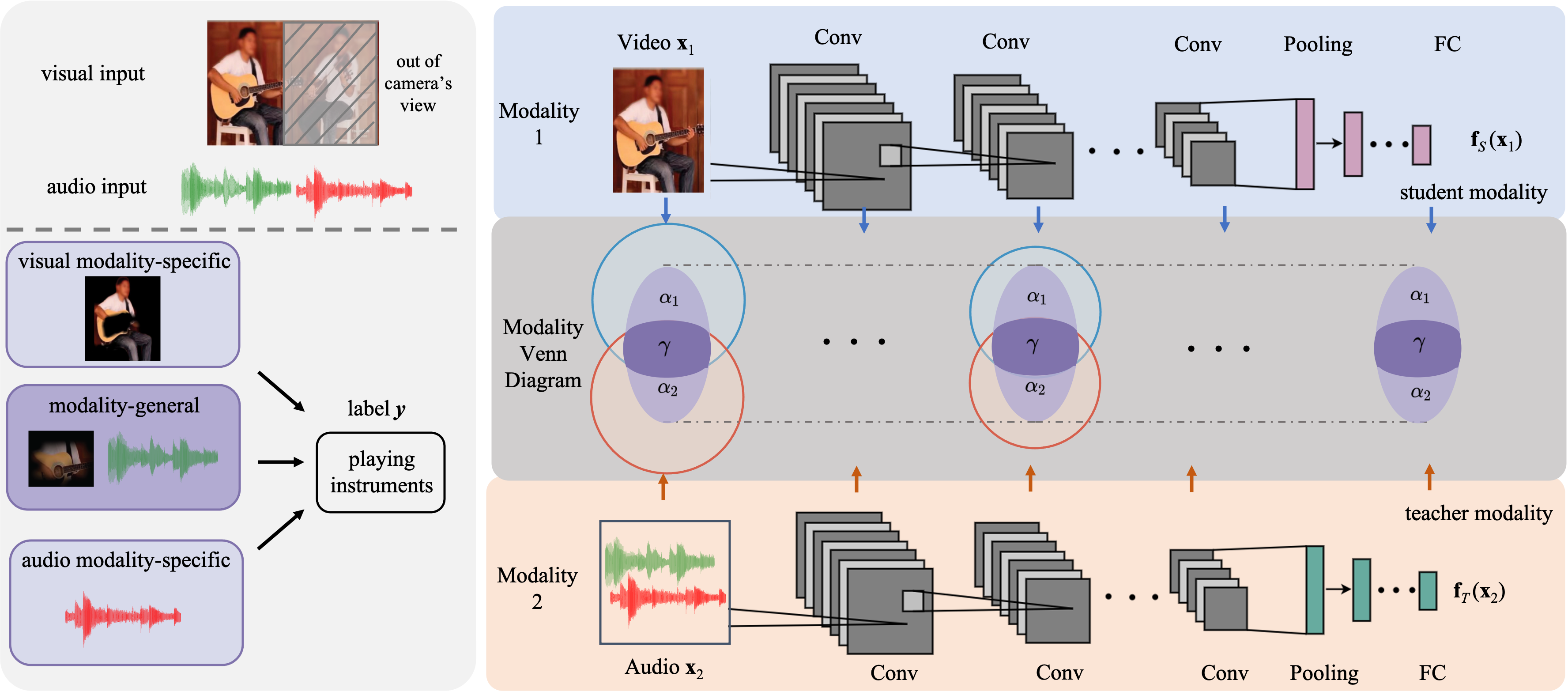
The Modality Focusing Hypothesis: Towards Understanding Crossmodal Knowledge Distillation
Zihui Xue*,
Zhengqi Gao*
Sucheng Ren*,
Hang Zhao
ICLR, 2023 (top-5%)[paper][webpage] When is crossmodal knowledge distillation helpful?
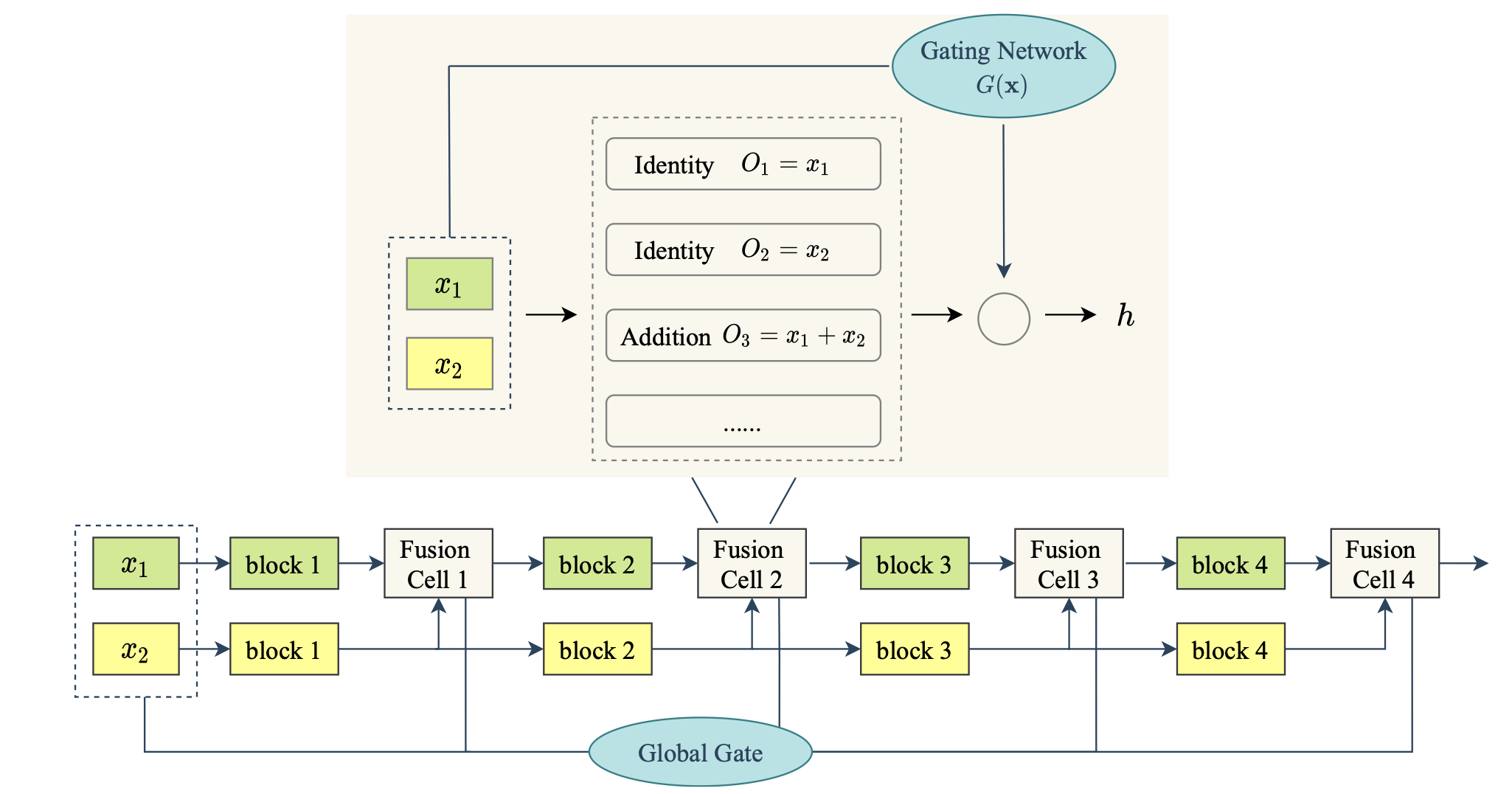
Dynamic Multimodal Fusion
Zihui Xue,
Radu Marculescu
CVPR MULA workshop, 2023[paper] Adaptively fuse multimodal data and generate data-dependent forward paths during inference time.
What Makes Multi-Modal Learning Better than Single (Provably)
Yu Huang,
Chenzhuang Du,
Zihui Xue,
Xuanyao Chen,
Hang Zhao,
Longbo Huang
NeurIPS, 2021[paper]
Can multimodal learning provably perform better than unimodal?
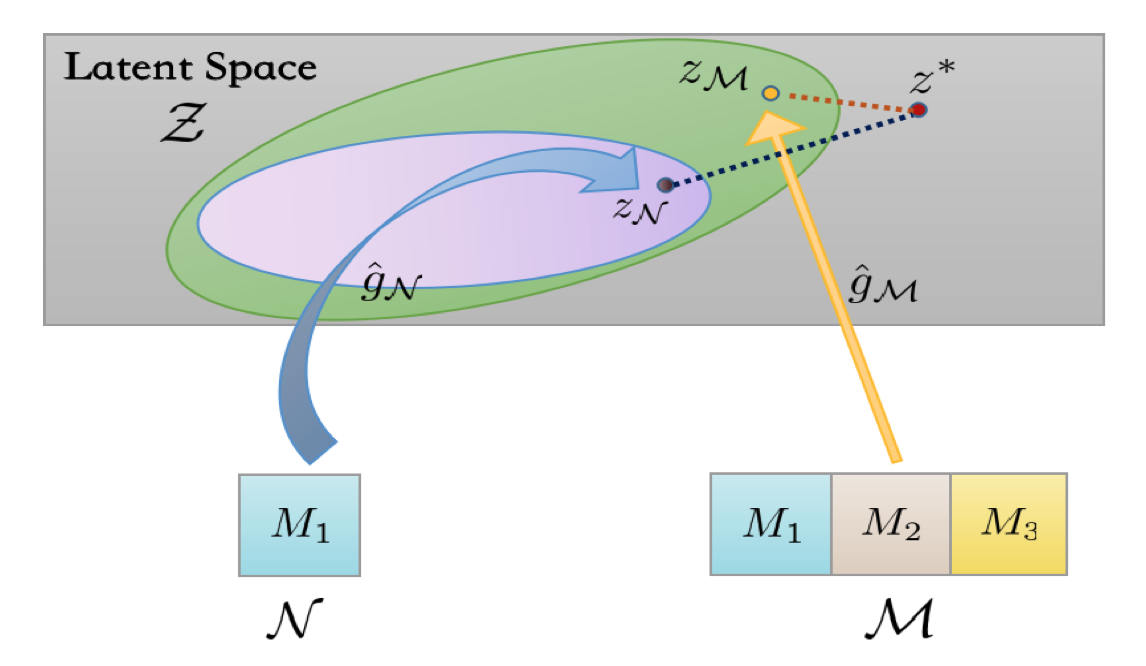
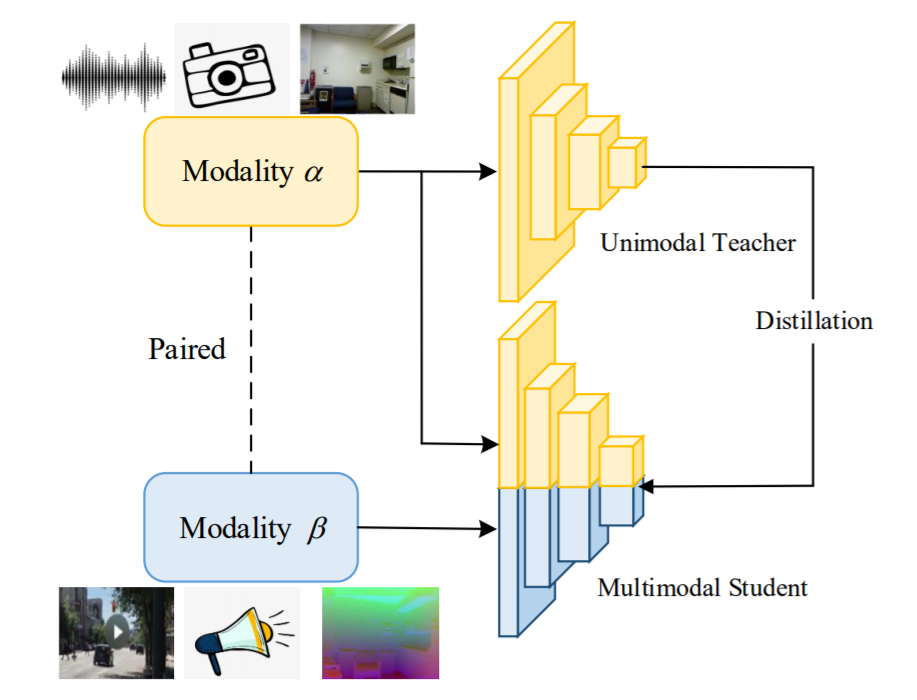
Multimodal Knowledge Expansion
Zihui Xue,
Sucheng Ren,
Zhengqi Gao,
Hang Zhao
ICCV, 2021
[paper][webpage]
A knowledge distillation-based framework to effectively utilize multimodal data without requiring labels.
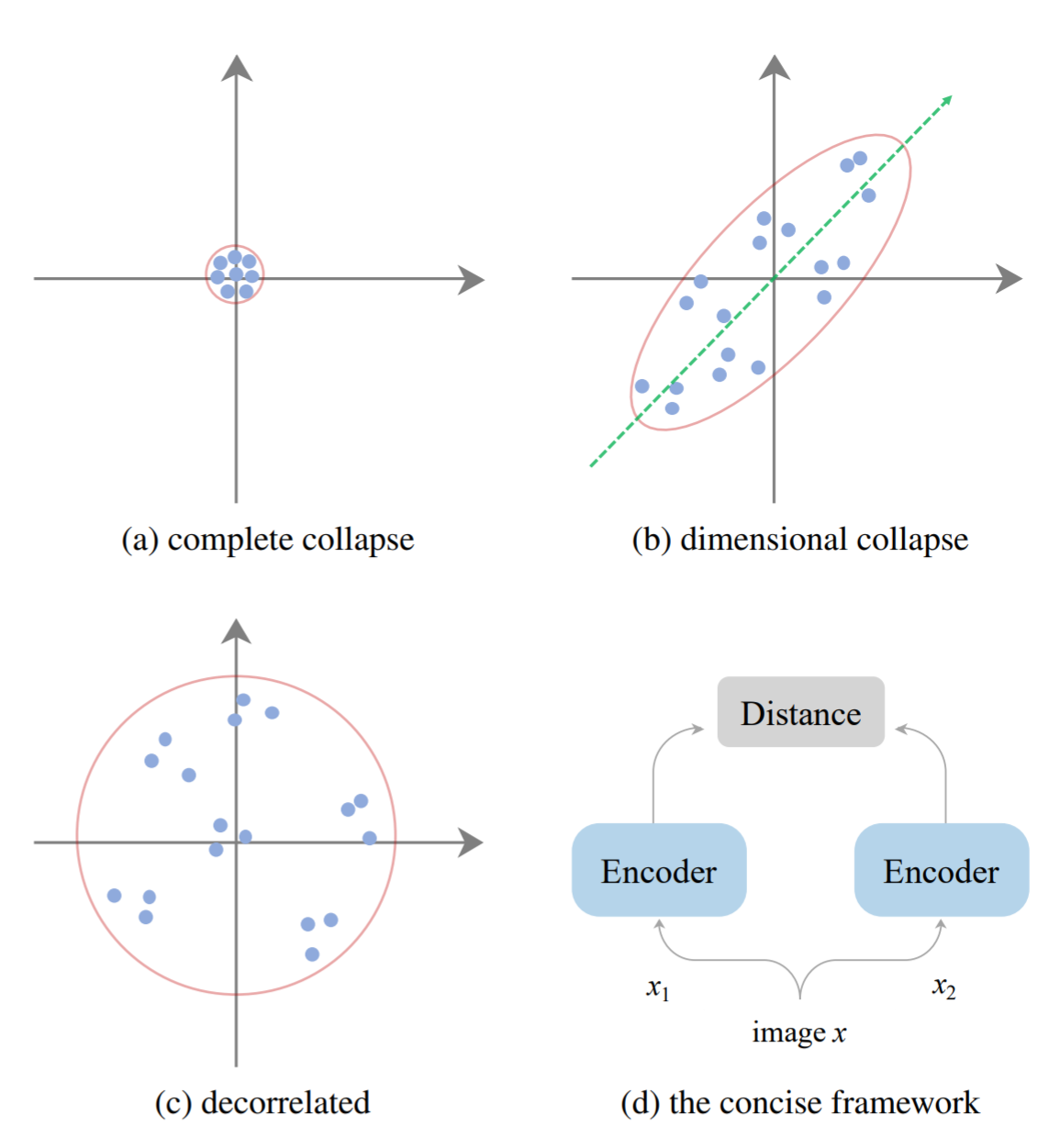
On Feature Decorrelation in Self-Supervised Learning
Tianyu Hua,
Wenxiao Wang,
Zihui Xue,
Sucheng Ren,
Yue Wang,
Hang Zhao
ICCV, 2021 (Oral, Acceptance Rate 3.0%)[paper][webpage]
Reveal the connection between model collapse and feature correlations!