The Modality Focusing Hypothesis: Towards Understanding Crossmodal Knowledge Distillation
ICLR 2023, top-5% (oral)
Abstract
Crossmodal knowledge distillation (KD) extends traditional knowledge distillation to the area of multimodal learning and demonstrates great success in various applications. To achieve knowledge transfer across modalities, a pretrained network from one modality is adopted as the teacher to provide supervision signals to a student network learning from another modality. In contrast to the empirical success reported in prior works, the working mechanism of crossmodal KD remains a mystery.
In this paper, we present a thorough understanding of crossmodal KD. We begin with two case studies and demonstrate that KD is not a universal cure in crossmodal knowledge transfer. We then present the modality Venn diagram to understand modality relationships and the modality focusing hypothesis revealing the decisive factor in the efficacy of crossmodal KD. Experimental results on 6 multimodal datasets help justify our hypothesis, diagnose failure cases, and point directions to improve crossmodal knowledge transfer in the future.
Motivation: crossmodal KD is not always helpful
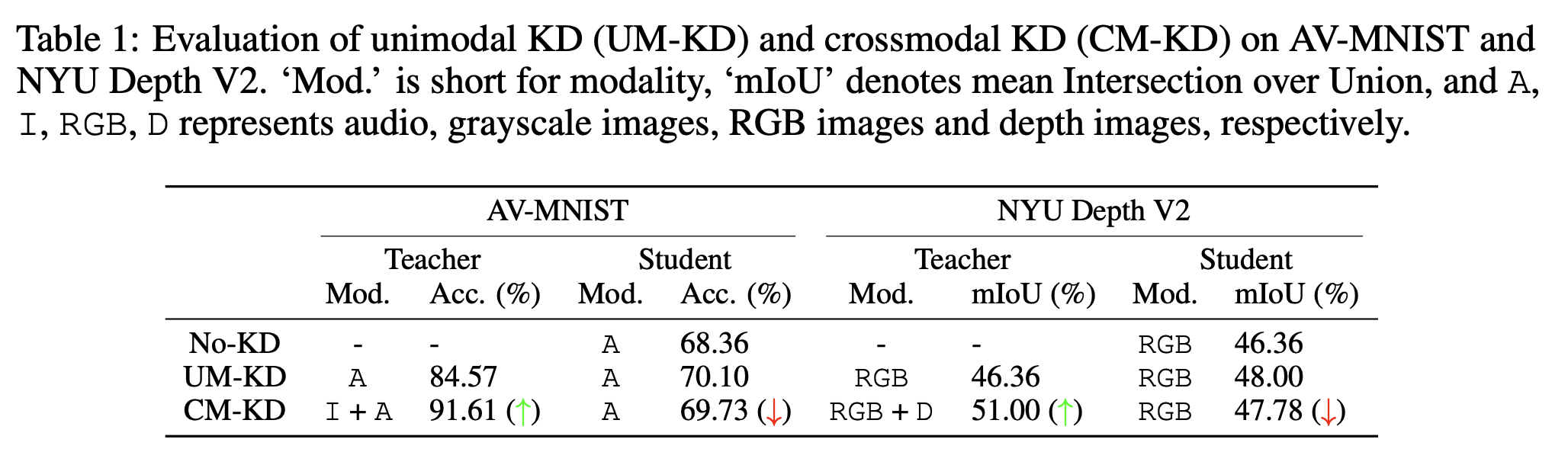
Even with the great increase in teacher accuracy, crossmodal KD fails to outperform unimodal KD in some cases. A more accurate teacher does not lead to a better student.
The Modality Venn Diagram (MVD)
Following a causal perspective (i.e., features cause labels), we assume that the label y is determined by a subset of features; this subset of features are referred to as decisive features.
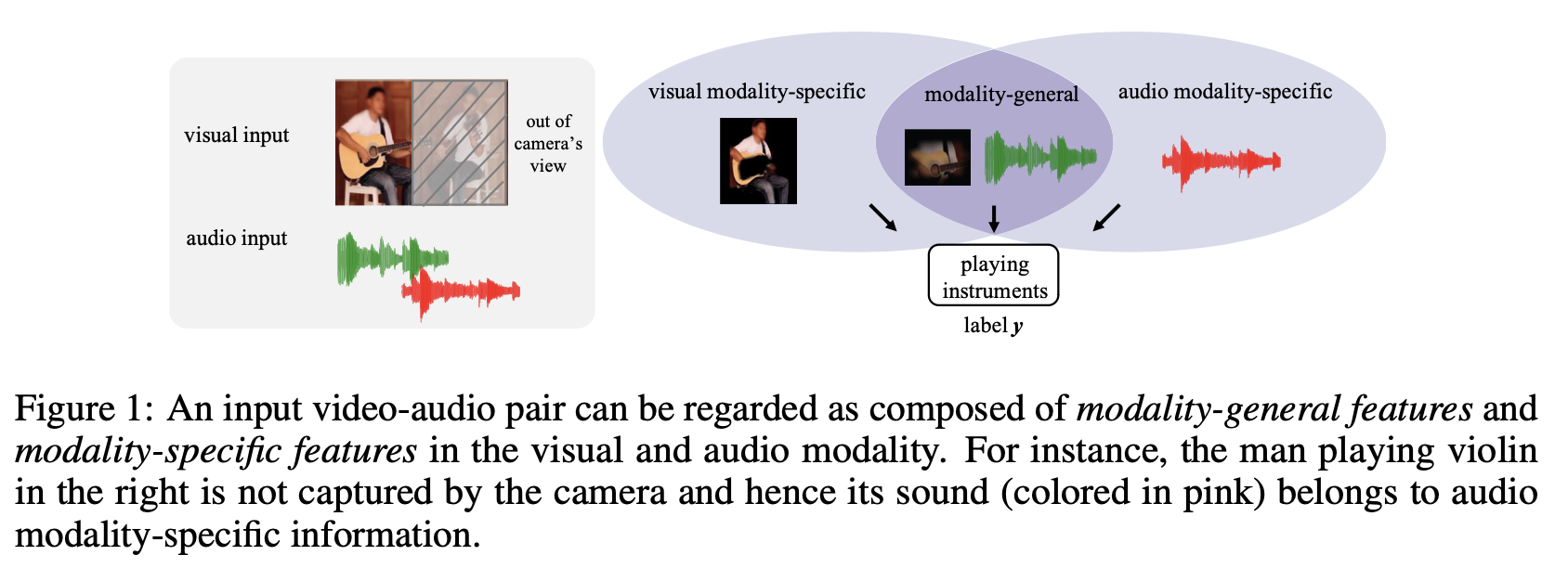
Stemming from the common perception that multimodal data possess shared information and preserve information specific to each modality, MVD states that any multimodal features are composed of modality-general features and modality-specific features.
Decisive features of the two modalities are thus composed of two parts: (1) modality-general decisive features and (2) modality-specific decisive features; these two parts of decisive features work together and contribute to the final label y.
The Modality Focusing Hypothesis (MFH)
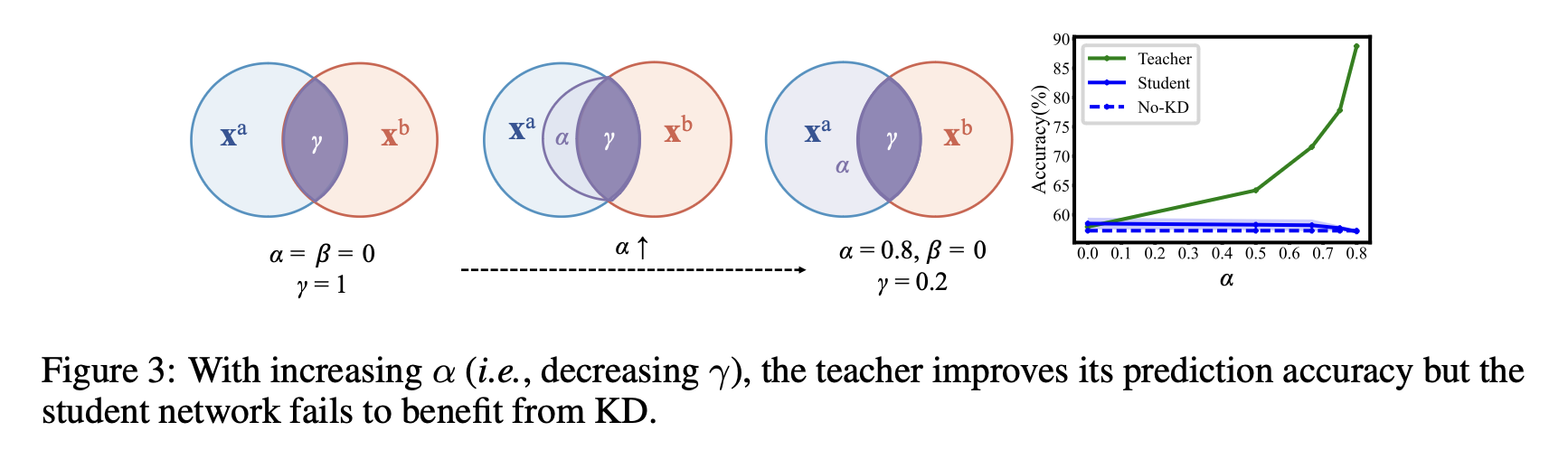
For crossmodal KD, distillation performance is dependent on the proportion of modality-general decisive features preserved in the teacher network: with larger γ, the student network is expected to perform better.

BibTeX
@inproceedings{xue2023modality,
title={The Modality Focusing Hypothesis: Towards Understanding Crossmodal Knowledge Distillation},
author={Xue, Zihui and Gao, Zhengqi and Ren, Sucheng and Zhao, Hang},
booktitle={ICLR},
year={2023}
}